Docker安装部署ELK Stack
ELK是什么:
ELK 是一个流行的日志分析和监控套件,包含三个主要组件:
- Elasticsearch:一个开源的搜索和分析引擎,用于存储和搜索大量的数据。它可以快速地对海量数据进行搜索和分析操作。
- Logstash:一个开源的数据处理管道,能够从不同的数据源收集、处理和转发数据。它支持各种输入源(如日志文件、网络数据流等),可以对数据进行过滤和转换,然后将其发送到 Elasticsearch 或其他存储系统。
- Kibana:一个开源的数据可视化平台,用于在 Elasticsearch 中创建和查看数据的图表和仪表盘。它提供了一个用户友好的界面,帮助用户探索和可视化存储在 Elasticsearch 中的数据。
ELK 套件通常用于集中化日志管理、数据分析和监控。通过将日志数据发送到 Logstash 进行处理,再存储到 Elasticsearch 中,并使用 Kibana 可视化数据,用户可以实时监控系统状态,分析日志数据中的趋势和异常。
安装说明:
1、Elasticsearch、Logstash、Kibana、Filebeat安装的版本号必须全部一致,不然会出现kibana无法显示web页面。
2、部署组件的服务器时间必须一致,否则会出现日志无法显示。
安装部署:
首先,确保你的系统上已安装 Docker 和 Docker Compose。如果尚未安装,可以使用以下命令进行安装:
# 安装 Docker
sudo dnf install -y docker
sudo systemctl start docker
sudo systemctl enable docker
# 安装 Docker Compose
sudo dnf install -y docker-compose
1.安装elasticsearch
官方网站:https://www.elastic.co/cn
Elasticsearch 介绍:
Elasticsearch 是一个开源的分布式搜索和分析引擎,广泛用于处理和分析大量的数据。它的核心功能包括全文搜索、结构化搜索和分析。
Elasticsearch的应用场景:
- 日志和事件数据分析:Elasticsearch 被广泛用于日志管理和事件数据分析,特别是与 Logstash 和 Kibana 结合使用时,形成了强大的 ELK Stack(Elasticsearch, Logstash, Kibana)。
- 网站搜索功能:许多网站和应用程序使用 Elasticsearch 为用户提供高效的搜索体验。
- 数据仓库和分析:Elasticsearch 可以作为数据仓库的一部分,用于存储和分析大规模的数据集,支持实时的数据探索和报告。
- 安全信息和事件管理(SIEM):它被用于安全信息和事件管理,帮助组织检测和响应安全事件
elasticsearch的安装方式:
- 二进制包(elasticsearch-8.14.2-linux-x86_64.tar.gz)安装:依赖于java,所以首先安装java环境-jdk、
- docker方式安装或者docker-compose.yml(elasticsearch:8.14.2)
这里使用docker方式安装
Linux下安装部署Docker二进制版本
1.1创建用于elk的网络
[root@C9146 elk]# docker network create elk
2469c547044d9fb40041ee49e1aa15bc60053261f7984171b341b984bba91ce0

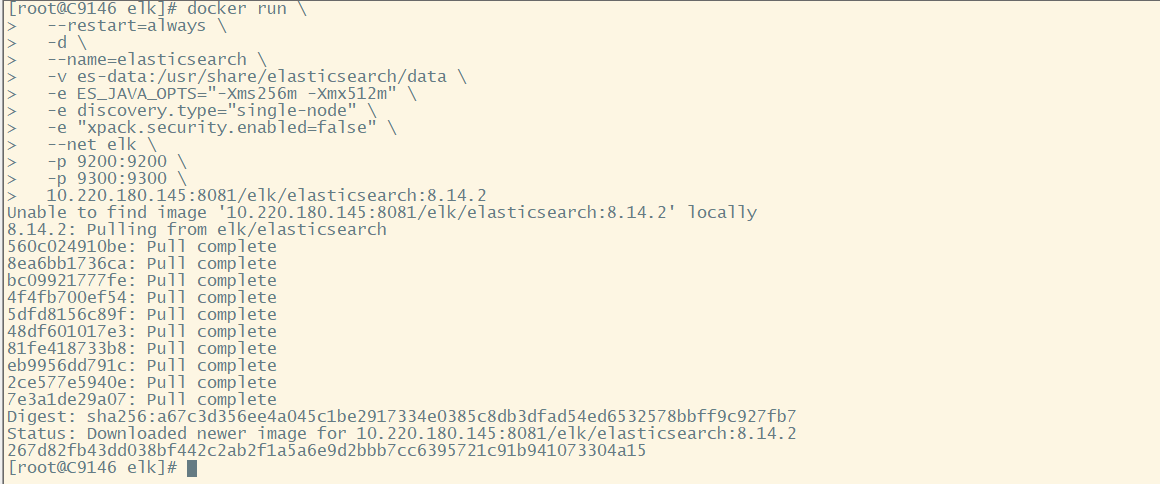
1.2 创建Elasticsearch容器
docker run \
--restart=always \
-d \
--name=elasticsearch \
-v es-data:/usr/share/elasticsearch/data \
-e ES_JAVA_OPTS="-Xms256m -Xmx512m" \
-e discovery.type="single-node" \
-e "xpack.security.enabled=false" \
--net elk \
-p 9200:9200 \
-p 9300:9300 \
10.220.180.145:8081/elk/elasticsearch:8.14.2
1.2.1 命令介绍:
- docker run:运行一个新的容器实例。
- –restart=always:设置容器在 Docker 启动时自动重启,以及容器退出时自动重启。
- -d:在后台运行容器。
- –name=elasticsearch:指定容器的名称为 elasticsearch。
- -v es-data:/usr/share/elasticsearch/data:将宿主机的 es-data 卷挂载到容器内的 /usr/share/elasticsearch/data 目录,用于持久化存储 Elasticsearch 数据。
- -e ES_JAVA_OPTS=”-Xms256m -Xmx512m”:设置 JVM 内存选项,-Xms 和 -Xmx 分别指定初始和最大堆内存大小。
- -e discovery.type=”single-node”:将 Elasticsearch 配置为单节点模式,这适用于开发和测试环境。
- -e “xpack.security.enabled=false”:禁用 X-Pack 安全功能,这样可以在没有认证的情况下访问 Elasticsearch。注意,禁用安全功能可能不适合生产环境。
- –net elk:将容器连接到名为 elk 的 Docker 网络,确保容器能够与其他在同一网络中的服务(如 Logstash 和 Kibana)通信。
- -p 9200:9200:将宿主机的 9200 端口映射到容器的 9200 端口,用于 HTTP 请求。
- -p 9300:9300:将宿主机的 9300 端口映射到容器的 9300 端口,用于集群内部的节点间通信。
- 10.220.180.145:8081/elk/elasticsearch:8.14.2:指定 Elasticsearch 镜像的地址和标签。(特别说明:这个地址是我自己部署的harbor仓库的地址,镜像是先下载然后上传到harbor仓库的)
1.3 查看运行的容器
docker ps
![]()
1.4 测试elasticsearch
curl http://127.0.0.1:9200/_cat/health curl http://localhost:9200/_cat/health

2. 安装kibana
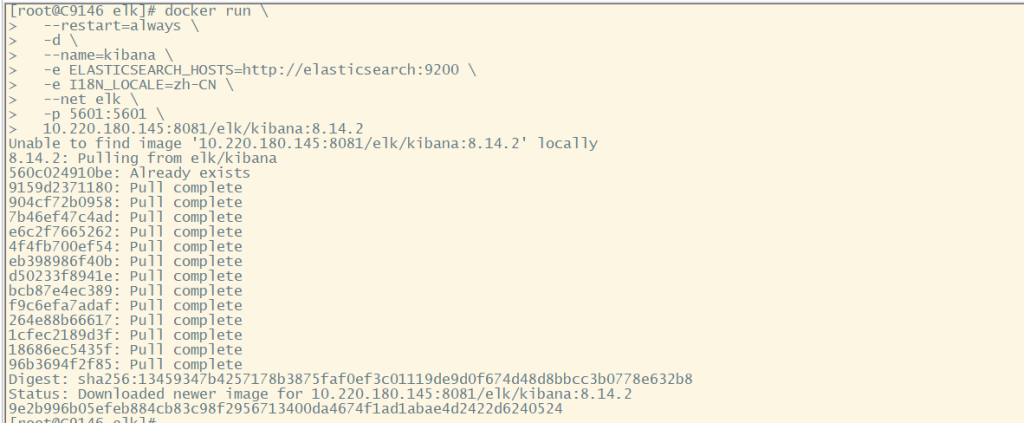
2.1创建kibana容器
docker run \
--restart=always \
-d \
--name=kibana \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
-e I18N_LOCALE=zh-CN \
--net elk \
-p 5601:5601 \
10.220.180.145:8081/elk/kibana:8.14.2
命令介绍:
- –restart=always:设置容器在 Docker 启动时自动重启,以及容器退出时自动重启。
- -d:在后台运行容器。
- –name=kibana:指定容器的名称为 kibana。
- -e ELASTICSEARCH_HOSTS=http://elasticsearch:9200:设置 Kibana 连接的 Elasticsearch 实例的地址。
- -e I18N_LOCALE=zh-CN:设置 Kibana 的国际化语言环境为中文。
- –net elk:将容器连接到名为 elk 的 Docker 网络。
- -p 5601:5601:将宿主机的 5601 端口映射到容器的 5601 端口,用于 Kibana 的 Web 界面访问。
- 10.220.180.145:8081/elk/kibana:8.14.2:指定 Kibana 镜像的地址和标签。
2.2 查看创建的容器
docker ps

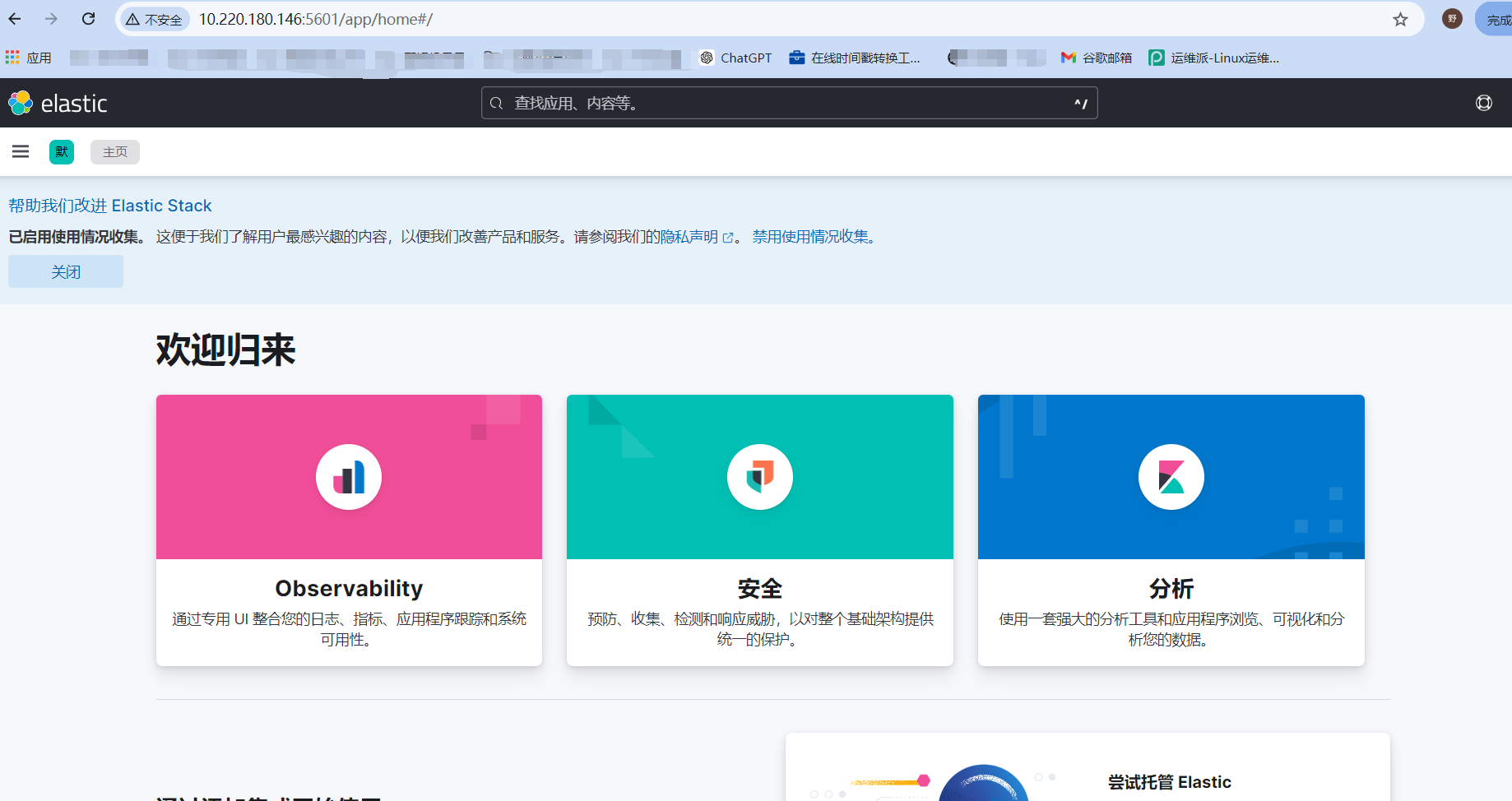
2.3 前端 ip:5601 访问测试
3.安装Filebeat(部署在被采集的日志服务器上)
下载地址:https://www.elastic.co/cn/downloads/past-releases
3.1 解压部署
rpm -ivh filebeat-8.14.2-x86_64.rpm systemctl enable --now filebeat.service systemctl status filebeat.service
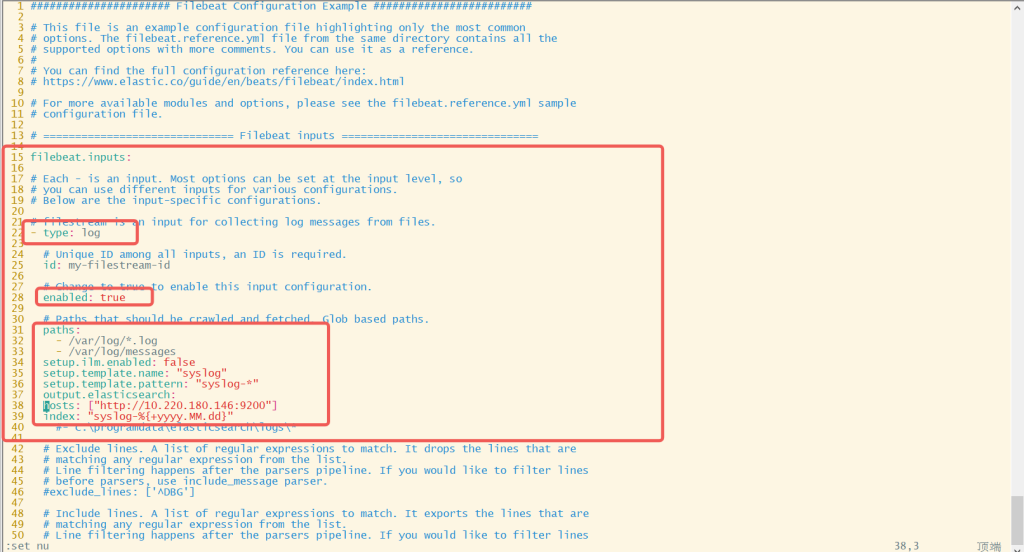
3.2 修改filebeat配置文件 /etc/filebeat/filebeat.yml ,使用filebeat采集日志
vim /etc/filebeat/filebeat.yml
15 filebeat.inputs:
16
17 # Each - is an input. Most options can be set at the input level, so
18 # you can use different inputs for various configurations.
19 # Below are the input-specific configurations.
20
21 # filestream is an input for collecting log messages from files.
22 - type: log
23
24 # Unique ID among all inputs, an ID is required.
25 id: my-filestream-id
26
27 # Change to true to enable this input configuration.
28 enabled: true
29
30 # Paths that should be crawled and fetched. Glob based paths.
31 paths:
32 - /var/log/*.log
33 - /var/log/messages
34 setup.ilm.enabled: false
35 setup.template.name: "syslog"
36 setup.template.pattern: "syslog-*"
37 output.elasticsearch:
38 hosts: ["http://10.220.180.146:9200"]
39 index: "syslog-%{+yyyy.MM.dd}"
40 #- c:\programdata\elasticsearch\logs\*
3.3 检测配置文件是否正确,重启服务使之生效
filebeat test config #检查配置文件是否正确 systemctl restart filebeat #重启服务

4. 前端配置查看数据
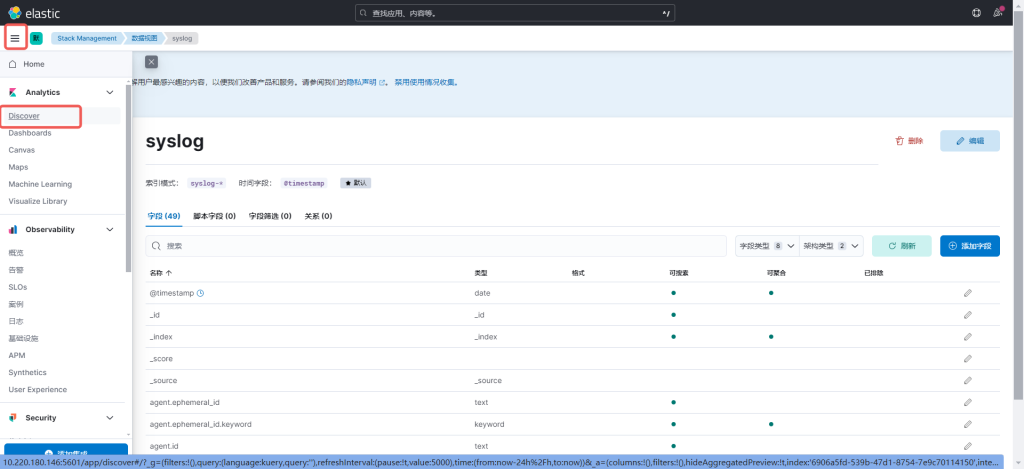
4.1登陆前端,点击Stack Management
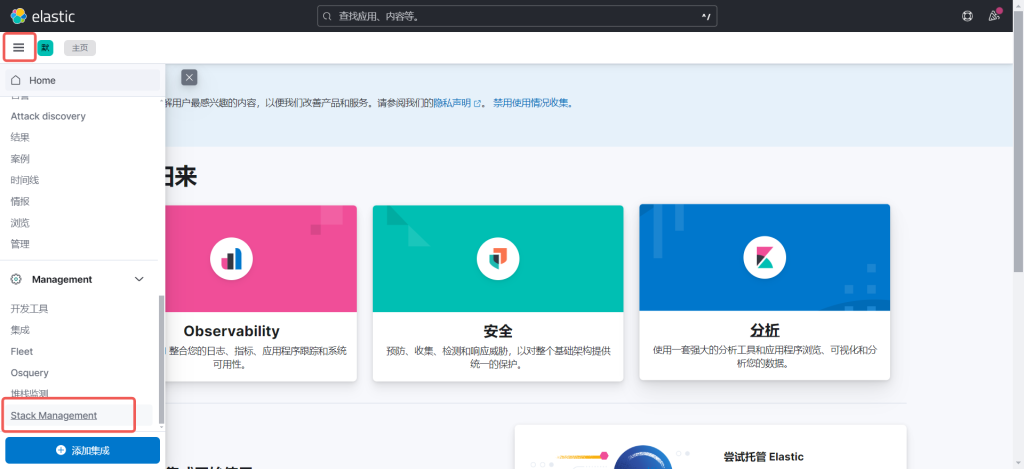
4.2 点击数据视图,4.1.2 点击数据视图,
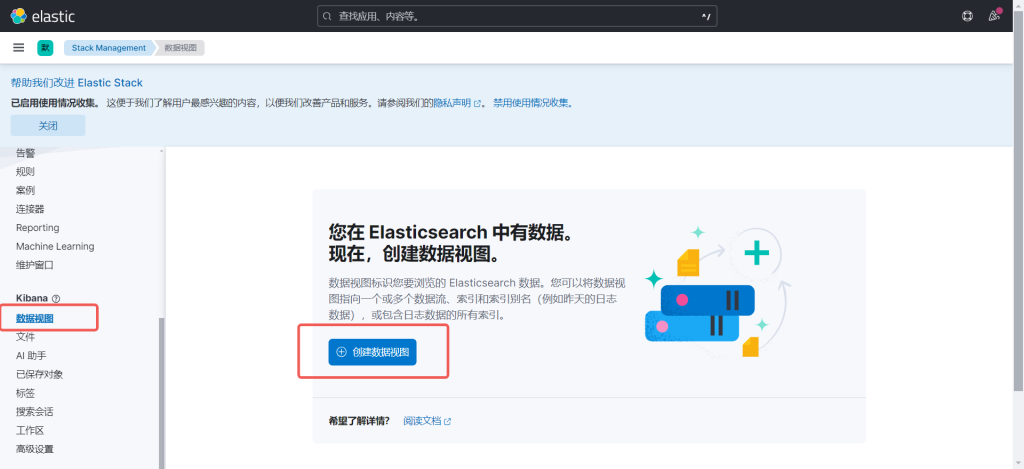
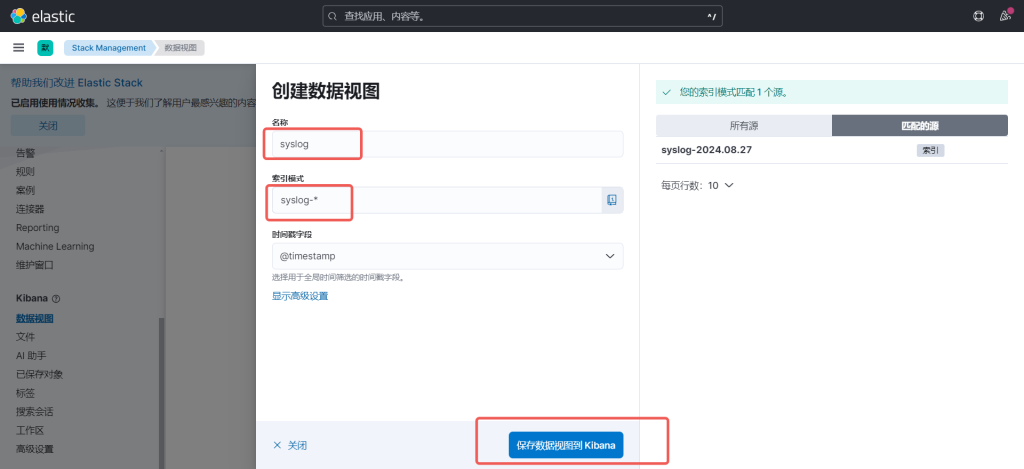
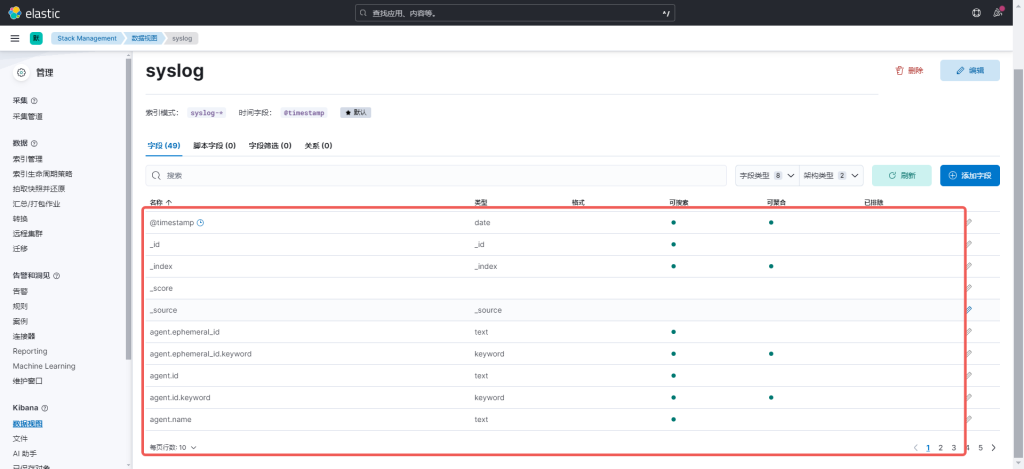
4.3 再点击Discover,就可以看见数据了